

This stylistic diagram shows a gene in relation to the double helix structure of DNA and to a chromosome (right). The chromosome is X-shaped because it is dividing. Introns are regions often found in eukaryote genes that are removed in the splicing process (after the DNA is transcribed into RNA): Only the exons encode the protein. This diagram labels a region of only 50 or so bases as a gene. In reality, most genes are hundreds of times larger.
A gene is a unit of heredity in a living organism. It is normally a stretch of DNA that codes for a type of protein or for an RNA chain that has a function in the organism. All proteins and functional RNA chains are specified by genes. All living things depend on genes. Genes hold the information to build and maintain an organism's cells and pass genetic traits to offspring. A modern working definition of a gene is "a locatable region of genomic sequence, corresponding to a unit of inheritance, which is associated with regulatory regions, transcribed regions, and or other functional sequence regions ".[1][2] Colloquial usage of the term gene (e.g. "good genes, "hair color gene") may actually refer to an allele: a gene is the basic instruction, a sequence of nucleic acid (DNA or, in the case of certain viruses RNA), while an allele is one variant of that instruction. Thus, when the mainstream press refers to "having" a "gene" for a specific trait, the press is wrong. All people would have the gene in question, but certain people will have a specific allele of that gene, which results in the trait.
The notion of a gene[3] is evolving with the science of genetics, which began when Gregor Mendel noticed that biological variations are inherited from parent organisms as specific, discrete traits. The biological entity responsible for defining traits was later termed a gene, but the biological basis for inheritance remained unknown until DNA was identified as the genetic material in the 1940s. All organisms have many genes corresponding to many different biological traits, some of which are immediately visible, such as eye color or number of limbs, and some of which are not, such as blood type or increased risk for specific diseases, or the thousands of basic biochemical processes that comprise life.
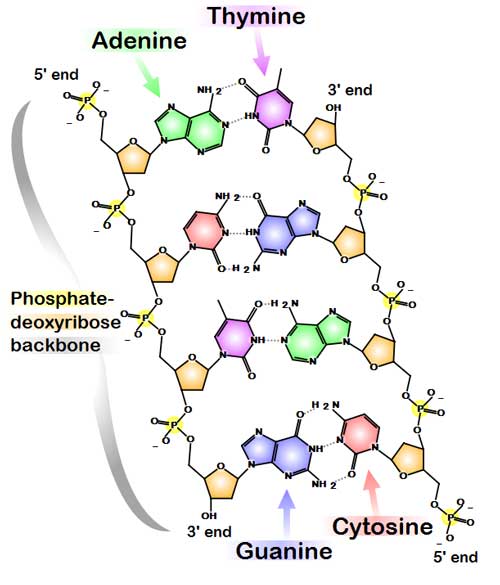
Chemical structure of a four-base fragment of a DNA double helix.. Hydrogen bonds shown as dotted lines. (Information about this image)
The vast majority of living organisms encode their genes in long strands of DNA. DNA (deoxyribonucleic acid) consists of a chain made from four types of nucleotide subunits, each composed of: a five-carbon sugar (2'-deoxyribose), a phosphate group, and one of the four bases adenine, cytosine, guanine, and thymine. The most common form of DNA in a cell is in a double helix structure, in which two individual DNA strands twist around each other in a right-handed spiral. In this structure, the base pairing rules specify that guanine pairs with cytosine and adenine pairs with thymine. The base pairing between guanine and cytosine forms three hydrogen bonds, whereas the base pairing between adenine and thymine forms two hydrogen bonds. The two strands in a double helix must therefore be complementary, that is, their bases must align such that the adenines of one strand are paired with the thymines of the other strand, and so on.
Due to the chemical composition of the pentose residues of the bases, DNA strands have directionality. One end of a DNA polymer contains an exposed hydroxyl group on the deoxyribose; this is known as the 3' end of the molecule. The other end contains an exposed phosphate group; this is the 5' end. The directionality of DNA is vitally important to many cellular processes, since double helices are necessarily directional (a strand running 5'-3' pairs with a complementary strand running 3'-5'), and processes such as DNA replication occur in only one direction. All nucleic acid synthesis in a cell occurs in the 5'-3' direction, because new monomers are added via a dehydration reaction that uses the exposed 3' hydroxyl as a nucleophile.
The expression of genes encoded in DNA begins by transcribing the gene into RNA, a second type of nucleic acid that is very similar to DNA, but whose monomers contain the sugar ribose rather than deoxyribose. RNA also contains the base uracil in place of thymine. RNA molecules are less stable than DNA and are typically single-stranded. Genes that encode proteins are composed of a series of three-nucleotide sequences called codons, which serve as the words in the genetic language. The genetic code specifies the correspondence during protein translation between codons and amino acids. The genetic code is nearly the same for all known organisms.
RNA genes and genomes
When proteins are manufactured, the gene is first copied into RNA as an intermediate product. In other cases, the RNA molecules are the actual functional products. For example, RNAs known as ribozymes are capable of enzymatic function, and microRNA has a regulatory role. The DNA sequences from which such RNAs are transcribed are known as RNA genes.
Some viruses store their entire genomes in the form of RNA, and contain no DNA at all. Because they use RNA to store genes, their cellular hosts may synthesize their proteins as soon as they are infected and without the delay in waiting for transcription. On the other hand, RNA retroviruses, such as HIV, require the reverse transcription of their genome from RNA into DNA before their proteins can be synthesized. In 2006, French researchers came across a puzzling example of RNA-mediated inheritance in mouse. Mice with a loss-of-function mutation in the gene Kit have white tails. Offspring of these mutants can have white tails despite having only normal Kit genes. The research team traced this effect back to mutated Kit RNA.[4] While RNA is common as genetic storage material in viruses, in mammals in particular RNA inheritance has been observed very rarely.
Functional structure of a gene

Diagram of the "typical" eukaryotic protein-coding gene. Promoters and enhancers determine what portions of the DNA will be transcribed into the precursor mRNA (pre-mRNA). The pre-mRNA is then spliced into messenger RNA (mRNA) which is later translated into protein.
All genes have regulatory regions in addition to regions that explicitly code for a protein or RNA product. A regulatory region shared by almost all genes is known as the promoter, which provides a position that is recognized by the transcription machinery when a gene is about to be transcribed and expressed. A gene can have more than one promoter, resulting in RNAs that differ in how far they extend in the 5' end.[5] Although promoter regions have a consensus sequence that is the most common sequence at this position, some genes have "strong" promoters that bind the transcription machinery well, and others have "weak" promoters that bind poorly. These weak promoters usually permit a lower rate of transcription than the strong promoters, because the transcription machinery binds to them and initiates transcription less frequently. Other possible regulatory regions include enhancers, which can compensate for a weak promoter. Most regulatory regions are "upstream"—that is, before or toward the 5' end of the transcription initiation site. Eukaryotic promoter regions are much more complex and difficult to identify than prokaryotic promoters.
Many prokaryotic genes are organized into operons, or groups of genes whose products have related functions and which are transcribed as a unit. By contrast, eukaryotic genes are transcribed only one at a time, but may include long stretches of DNA called introns which are transcribed but never translated into protein (they are spliced out before translation). Splicing can also occur in prokaryotic genes, but is less common than in eukaryotes.[6]
Chromosomes
The total complement of genes in an organism or cell is known as its genome, which may be stored on one or more chromosomes; the region of the chromosome at which a particular gene is located is called its locus. A chromosome consists of a single, very long DNA helix on which thousands of genes are encoded. Prokaryotes—bacteria and archaea—typically store their genomes on a single large, circular chromosome, sometimes supplemented by additional small circles of DNA called plasmids, which usually encode only a few genes and are easily transferable between individuals. For example, the genes for antibiotic resistance are usually encoded on bacterial plasmids and can be passed between individual cells, even those of different species, via horizontal gene transfer. Although some simple eukaryotes also possess plasmids with small numbers of genes, the majority of eukaryotic genes are stored on multiple linear chromosomes, which are packed within the nucleus in complex with storage proteins called histones. The manner in which DNA is stored on the histone, as well as chemical modifications of the histone itself, are regulatory mechanisms governing whether a particular region of DNA is accessible for gene expression. The ends of eukaryotic chromosomes are capped by long stretches of repetitive sequences called telomeres, which do not code for any gene product but are present to prevent degradation of coding and regulatory regions during DNA replication. The length of the telomeres tends to decrease each time the genome is replicated in preparation for cell division; the loss of telomeres has been proposed as an explanation for cellular senescence, or the loss of the ability to divide, and by extension for the aging process in organisms.[7]
Whereas the chromosomes of prokaryotes are relatively gene-dense, those of eukaryotes often contain so-called "junk DNA", or regions of DNA that serve no obvious function. Simple single-celled eukaryotes have relatively small amounts of such DNA, whereas the genomes of complex multicellular organisms, including humans, contain an absolute majority of DNA without an identified function.[8] However it now appears that, although protein-coding DNA makes up barely 2% of the human genome, about 80% of the bases in the genome may be being expressed, so the term "junk DNA" may be a misnomer.[2]
Gene expression
Main article: Gene expression
In all organisms, there are two major steps separating a protein-coding gene from its protein: First, the DNA on which the gene resides must be transcribed from DNA to messenger RNA (mRNA); and, second, it must be translated from mRNA to protein. RNA-coding genes must still go through the first step, but are not translated into protein. The process of producing a biologically functional molecule of either RNA or protein is called gene expression, and the resulting molecule itself is called a gene product.
Genetic code
Main article: Genetic code
Schematic diagram of a single-stranded RNA molecule illustrating the position of three-base codons.
The genetic code is the set of rules by which a gene is translated into a functional protein. Each gene consists of a specific sequence of nucleotides encoded in a DNA (or sometimes RNA) strand; a correspondence between nucleotides, the basic building blocks of genetic material, and amino acids, the basic building blocks of proteins, must be established for genes to be successfully translated into functional proteins. Sets of three nucleotides, known as codons, each correspond to a specific amino acid or to a signal; three codons are known as "stop codons" and, instead of specifying a new amino acid, alert the translation machinery that the end of the gene has been reached. There are 64 possible codons (four possible nucleotides at each of three positions, hence 43 possible codons) and only 20 standard amino acids; hence the code is redundant and multiple codons can specify the same amino acid. The correspondence between codons and amino acids is nearly universal among all known living organisms.
Transcription
The process of genetic transcription produces a single-stranded RNA molecule known as messenger RNA, whose nucleotide sequence is complementary to the DNA from which it was transcribed. The DNA strand whose sequence matches that of the RNA is known as the coding strand and the strand from which the RNA was synthesized is the template strand. Transcription is performed by an enzyme called an RNA polymerase, which reads the template strand in the 3' to 5' direction and synthesizes the RNA from 5' to 3'. To initiate transcription, the polymerase first recognizes and binds a promoter region of the gene. Thus a major mechanism of gene regulation is the blocking or sequestering of the promoter region, either by tight binding by repressor molecules that physically block the polymerase, or by organizing the DNA so that the promoter region is not accessible.
In prokaryotes, transcription occurs in the cytoplasm; for very long transcripts, translation may begin at the 5' end of the RNA while the 3' end is still being transcribed. In eukaryotes, transcription necessarily occurs in the nucleus, where the cell's DNA is sequestered; the RNA molecule produced by the polymerase is known as the primary transcript and must undergo post-transcriptional modifications before being exported to the cytoplasm for translation. The splicing of introns present within the transcribed region is a modification unique to eukaryotes; alternative splicing mechanisms can result in mature transcripts from the same gene having different sequences and thus coding for different proteins. This is a major form of regulation in eukaryotic cells.
Translation
Translation is the process by which a mature mRNA molecule is used as a template for synthesizing a new protein. Translation is carried out by ribosomes, large complexes of RNA and protein responsible for carrying out the chemical reactions to add new amino acids to a growing polypeptide chain by the formation of peptide bonds. The genetic code is read three nucleotides at a time, in units called codons, via interactions with specialized RNA molecules called transfer RNA (tRNA). Each tRNA has three unpaired bases known as the anticodon that are complementary to the codon it reads; the tRNA is also covalently attached to the amino acid specified by the complementary codon. When the tRNA binds to its complementary codon in an mRNA strand, the ribosome ligates its amino acid cargo to the new polypeptide chain, which is synthesized from amino terminus to carboxyl terminus. During and after its synthesis, the new protein must fold to its active three-dimensional structure before it can carry out its cellular function.
DNA replication and inheritance
The growth, development, and reproduction of organisms relies on cell division, or the process by which a single cell divides into two usually identical daughter cells. This requires first making a duplicate copy of every gene in the genome in a process called DNA replication. The copies are made by specialized enzymes known as DNA polymerases, which "read" one strand of the double-helical DNA, known as the template strand, and synthesize a new complementary strand. Because the DNA double helix is held together by base pairing, the sequence of one strand completely specifies the sequence of its complement; hence only one strand needs to be read by the enzyme to produce a faithful copy. The process of DNA replication is semiconservative; that is, the copy of the genome inherited by each daughter cell contains one original and one newly synthesized strand of DNA.[9]
After DNA replication is complete, the cell must physically separate the two copies of the genome and divide into two distinct membrane-bound cells. In prokaryotes - bacteria and archaea - this usually occurs via a relatively simple process called binary fission, in which each circular genome attaches to the cell membrane and is separated into the daughter cells as the membrane invaginates to split the cytoplasm into two membrane-bound portions. Binary fission is extremely fast compared to the rates of cell division in eukaryotes. Eukaryotic cell division is a more complex process known as the cell cycle; DNA replication occurs during a phase of this cycle known as S phase, whereas the process of segregating chromosomes and splitting the cytoplasm occurs during M phase. In many single-celled eukaryotes such as yeast, reproduction by budding is common, which results in asymmetrical portions of cytoplasm in the two daughter cells.
Molecular inheritance
The duplication and transmission of genetic material from one generation of cells to the next is the basis for molecular inheritance, and the link between the classical and molecular pictures of genes. Organisms inherit the characteristics of their parents because the cells of the offspring contain copies of the genes in their parents' cells. In asexually reproducing organisms, the offspring will be a genetic copy or clone of the parent organism. In sexually reproducing organisms, a specialized form of cell division called meiosis produces cells called gametes or germ cells that are haploid, or contain only one copy of each gene. The gametes produced by females are called eggs or ova, and those produced by males are called sperm. Two gametes fuse to form a fertilized egg, a single cell that once again has a diploid number of genes—each with one copy from the mother and one copy from the father.
During the process of meiotic cell division, an event called genetic recombination or crossing-over can sometimes occur, in which a length of DNA on one chromatid is swapped with a length of DNA on the corresponding sister chromatid. This has no effect if the alleles on the chromatids are the same, but results in reassortment of otherwise linked alleles if they are different. The Mendelian principle of independent assortment asserts that each of a parent's two genes for each trait will sort independently into gametes; which allele an organism inherits for one trait is unrelated to which allele it inherits for another trait. This is in fact only true for genes that do not reside on the same chromosome, or are located very far from one another on the same chromosome. The closer two genes lie on the same chromosome, the more closely they will be associated in gametes and the more often they will appear together; genes that are very close are essentially never separated because it is extremely unlikely that a crossover point will occur between them. This is known as genetic linkage.
History
Main article: History of genetics
Prior to Mendel's work, the dominant theory of heredity was one of blending inheritance, which proposes that the traits of the parents blend or mix in a smooth, continuous gradient in the offspring. Although Mendel's work was largely unrecognized after its first publication in 1866, it was rediscovered in 1900 by three European scientists, Hugo de Vries, Carl Correns, and Erich von Tschermak, who had reached similar conclusions from their own research. However, these scientists were not yet aware of the identity of the 'discrete units' on which genetic material resides.
The existence of genes was first suggested by Gregor Mendel (1822–1884), who, in the 1860s, studied inheritance in peaplants (Pisum sativum) and hypothesized a factor that conveys traits from parent to offspring. He spent over 10 years of his life on one experiment. Although he did not use the term gene, he explained his results in terms of inherited characteristics. Mendel was also the first to hypothesize independent assortment, the distinction between dominant and recessive traits, the distinction between a heterozygote and homozygote, and the difference between what would later be described as genotype (the genetic material of an organism) and phenotype (the visible traits of that organism). Mendel's concept was given a name by Hugo de Vries in 1889, who, at that time probably unaware of Mendel's work, in his book Intracellular Pangenesis coined the term "pangen" for "the smallest particle [representing] one hereditary characteristic".[10]
Darwin used the term Gemmule to describe a microscopic unit of inheritance, and what would later become known as Chromosomes had been observed separating out during cell division by Wilhelm Hofmeister as early as 1848. The idea that chromosomes are the carriers of inheritance was expressed in 1883 by Wilhelm Roux. The modern conception of the gene originated with work by Gregor Mendel, a 19th-century Augustinian monk who systematically studied heredity in pea plants. Mendel's work was the first to illustrate particulate inheritance, or the theory that inherited traits are passed from one generation to the next in discrete units that interact in well-defined ways. Danish botanist Wilhelm Johannsen coined the word "gene" ("gen" in Danish and German) in 1909 to describe these fundamental physical and functional units of heredity,[11] while the related word genetics was first used by William Bateson in 1905.[12] The word was derived from Hugo de Vries' 1889 term pangen for the same concept,[10] itself a derivative of the word pangenesis coined by Darwin (1868).[13] The word pangenesis is made from the Greek words pan (a prefix meaning "whole", "encompassing") and genesis ("birth") or genos ("origin").
In the early 1900s, Mendel's work received renewed attention from scientists. In 1910, Thomas Hunt Morgan showed that genes reside on specific chromosomes. He later showed that genes occupy specific locations on the chromosome. With this knowledge, Morgan and his students began the first chromosomal map of the fruit fly Drosophila. In 1928, Frederick Griffith showed that genes could be transferred. In what is now known as Griffith's experiment, injections into a mouse of a deadly strain of bacteria that had been heat-killed transferred genetic information to a safe strain of the same bacteria, killing the mouse.
A series of subsequent discoveries led to the realization decades later that chromosomes within cells are the carriers of genetic material, and that they are made of DNA (deoxyribonucleic acid), a polymeric molecule found in all cells on which the 'discrete units' of Mendelian inheritance are encoded.
In 1941, George Wells Beadle and Edward Lawrie Tatum showed that mutations in genes caused errors in specific steps in metabolic pathways. This showed that specific genes code for specific proteins, leading to the "one gene, one enzyme" hypothesis.[12] Oswald Avery, Colin Munro MacLeod, and Maclyn McCarty showed in 1944 that DNA holds the gene's information.[14] In 1953, James D. Watson and Francis Crick demonstrated the molecular structure of DNA. Together, these discoveries established the central dogma of molecular biology, which states that proteins are translated from RNA which is transcribed from DNA. This dogma has since been shown to have exceptions, such as reverse transcription in retroviruses.
In 1972, Walter Fiers and his team at the Laboratory of Molecular Biology of the University of Ghent (Ghent, Belgium) were the first to determine the sequence of a gene: the gene for Bacteriophage MS2 coat protein.[15] Richard J. Roberts and Phillip Sharp discovered in 1977 that genes can be split into segments. This led to the idea that one gene can make several proteins. Recently (as of 2003–2006), biological results let the notion of gene appear more slippery. In particular, genes do not seem to sit side by side on DNA like discrete beads. Instead, regions of the DNA producing distinct proteins may overlap, so that the idea emerges that "genes are one long continuum".[1]
It was first hypothesized in 1986 by Walter Gilbert that neither DNA nor protein would be required in such a primitive system as that of a very early stage of the earth if RNA could perform as simply a catalyst and genetic information storage processor[2].
The modern study of genetics at the level of DNA is known as molecular genetics and the synthesis of molecular genetics with traditional Darwinian evolution is known as the modern evolutionary synthesis.
Mendelian inheritance and classical genetics
Main articles: Mendelian inheritance and Classical genetics
Crossing between two pea plants heterozygous for purple (B, dominant) and white (b, recessive) blossoms
According to the theory of Mendelian inheritance, variations in phenotype—the observable physical and behavioral characteristics of an organism—are due to variations in genotype, or the organism's particular set of genes, each of which specifies a particular trait. Different forms of a gene, which may give rise to different phenotypes, are known as alleles. Organisms such as the pea plants Mendel worked on, along with many plants and animals, have two alleles for each trait, one inherited from each parent. Alleles may be dominant or recessive; dominant alleles give rise to their corresponding phenotypes when paired with any other allele for the same trait, whereas recessive alleles give rise to their corresponding phenotype only when paired with another copy of the same allele. For example, if the allele specifying tall stems in pea plants is dominant over the allele specifying short stems, then pea plants that inherit one tall allele from one parent and one short allele from the other parent will also have tall stems. Mendel's work found that alleles assort independently in the production of gametes, or germ cells, ensuring variation in the next generation.
Mutation
Main article: Mutation
DNA replication is for the most part extremely accurate, with an error rate per site of around 10−6 to 10−10 in eukaryotes.[9] Rare, spontaneous alterations in the base sequence of a particular gene arise from a number of sources, such as errors in DNA replication and the aftermath of DNA damage. These errors are called mutations. The cell contains many DNA repair mechanisms for preventing mutations and maintaining the integrity of the genome; however, in some cases—such as breaks in both DNA strands of a chromosome — repairing the physical damage to the molecule is a higher priority than producing an exact copy. Due to the degeneracy of the genetic code, some mutations in protein-coding genes are silent, or produce no change in the amino acid sequence of the protein for which they code; for example, the codons UCU and UUC both code for serine, so the U↔C mutation has no effect on the protein. Mutations that do have phenotypic effects are most often neutral or deleterious to the organism, but sometimes they confer benefits to the organism's fitness.
Mutations propagated to the next generation lead to variations within a species' population. Variants of a single gene are known as alleles, and differences in alleles may give rise to differences in traits. Although it is rare for the variants in a single gene to have clearly distinguishable phenotypic effects, certain well-defined traits are in fact controlled by single genetic loci. A gene's most common allele is called the wild type allele, and rare alleles are called mutants. However, this does not imply that the wild-type allele is the ancestor from which the mutants are descended.
Genome
Chromosomal organization
The total complement of genes in an organism or cell is known as its genome. In prokaryotes, the vast majority of genes are located on a single chromosome of circular DNA, while eukaryotes usually possess multiple individual linear DNA helices packed into dense DNA-protein complexes called chromosomes. Genes that appear together on one chromosome of one species may appear on separate chromosomes in another species. Many species carry more than one copy of their genome within each of their somatic cells. Cells or organisms with only one copy of each chromosome are called haploid; those with two copies are called diploid; and those with more than two copies are called polyploid. The copies of genes on the chromosomes are not necessarily identical. In sexually reproducing organisms, one copy is normally inherited from each parent.
Number of genes
Early estimates of the number of human genes that used expressed sequence tag data put it at 50 000–100 000.[16] Following the sequencing of the human genome and other genomes, it has been found that rather few genes (~20 000 in human, mouse and fly, ~13 000 in roundworm, >46 000 in rice) encode all the proteins in an organism.[17] These protein-coding sequences make up 1–2% of the human genome.[18] A large part of the genome is transcribed however, to introns, retrotransposons and seemingly a large array of noncoding RNAs.[17][18]
Genetic and genomic nomenclature
Gene nomenclature has been established by the HUGO Gene Nomenclature Committee (HGNC) for each known human gene in the form of an approved gene name and symbol (short-form abbreviation). All approved symbols are stored in the HGNC Database. Each symbol is unique and each gene is only given one approved gene symbol. It is necessary to provide a unique symbol for each gene so that people can talk about them. This also facilitates electronic data retrieval from publications. In preference each symbol maintains parallel construction in different members of a gene family and can be used in other species, especially the mouse.
Evolutionary concept of a gene
George C. Williams first explicitly advocated the gene-centric view of evolution in his 1966 book Adaptation and Natural Selection. He proposed an evolutionary concept of gene to be used when we are talking about natural selection favoring some genes. The definition is: "that which segregates and recombines with appreciable frequency." According to this definition, even an asexual genome could be considered a gene, insofar that it have an appreciable permanency through many generations.
The difference is: the molecular gene transcribes as a unit, and the evolutionary gene inherits as a unit.
Richard Dawkins' books The Selfish Gene (1976) and The Extended Phenotype (1982) defended the idea that the gene is the only replicator in living systems. This means that only genes transmit their structure largely intact and are potentially immortal in the form of copies. So, genes should be the unit of selection. In The Selfish Gene Dawkins attempts to redefine the word 'gene' to mean "an inheritable unit" instead of the generally accepted definition of "a section of DNA coding for a particular protein". In River Out of Eden, Dawkins further refined the idea of gene-centric selection by describing life as a river of compatible genes flowing through geological time. Scoop up a bucket of genes from the river of genes, and we have an organism serving as temporary bodies or survival machines. A river of genes may fork into two branches representing two non-interbreeding species as a result of geographical separation.
Gene targeting and implications
Main article: Gene targeting
Gene targeting is commonly referred to techniques for altering or disrupting mouse genes and provides the mouse models for studying the roles of individual genes in embryonic development, human disorders, aging and diseases. The mouse models, where one or more of its genes are deactivated or made inoperable, are called knockout mice. Since the first reports in which homologous recombination in embryonic stem cells was used to generate gene-targeted mice,[19] gene targeting has proven to be a powerful means of precisely manipulating the mammalian genome, producing at least ten thousand mutant mouse strains and it is now possible to introduce mutations that can be activated at specific time points, or in specific cells or organs, both during development and in the adult animal.[20][21]
Gene targeting strategies have been expanded to all kinds of modifications, including point mutations, isoform deletions, mutant allele correction, large pieces of chromosomal DNA insertion and deletion, tissue specific disruption combined with spatial and temporal regulation and so on. It is predicted that the ability to generate mouse models with predictable phenotypes will have a major impact on studies of all phases of development, immunology, neurobiology, oncology, physiology, metabolism, and human diseases. Gene targeting is also in theory applicable to species from which totipotent embryonic stem cells can be established, and therefore may offer a potential to the improvement of domestic animals and plants.[21][22]
Changing concept
The concept of the gene has changed considerably (see history section). From the original definition of a "unit of inheritance", the term evolved to mean a DNA-based unit that can exert its effects on the organism through RNA or protein products. It was also previously believed that one gene makes one protein; this concept was overthrown by the discovery of alternative splicing and trans-splicing.[12]
The definition of a gene is still changing. The first cases of RNA-based inheritance have been discovered in mammals.[4] Evidence is also accumulating that the control regions of a gene do not necessarily have to be close to the coding sequence on the linear molecule or even on the same chromosome. Spilianakis and colleagues discovered that the promoter region of the interferon-gamma gene on chromosome 10 and the regulatory regions of the T(H)2 cytokine locus on chromosome 11 come into close proximity in the nucleus possibly to be jointly regulated.[23]
The concept that genes are clearly delimited is also being eroded. There is evidence for fused proteins stemming from two adjacent genes that can produce two separate protein products. While it is not clear whether these fusion proteins are functional, the phenomenon is more frequent than previously thought.[24] Even more ground-breaking than the discovery of fused genes is the observation that some proteins can be composed of exons from far away regions and even different chromosomes.[2][25] This new data has led to an updated, and probably tentative, definition of a gene as "a union of genomic sequences encoding a coherent set of potentially overlapping functional products."[12] This new definition categorizes genes by functional products, whether they be proteins or RNA, rather than specific DNA loci; all regulatory elements of DNA are therefore classified as gene-associated regions.[12]
See also
* Copy number variation
* DNA
* Full genome sequencing
* Epigenetics
* Gene-centric view of evolution
* Gene dosage
* Gene expression
* Gene family
* Gene pool
* Gene redundancy
* Gene therapy
* Genetic algorithm
* Genetic Engineering
* Genetics
* Genome
* Genomics
* List of notable genes
* Meme
* Pseudogene
* Predictive medicine
References
1. ^ a b Pearson H (2006). "Genetics: what is a gene?". Nature 441 (7092): 398–401. doi:10.1038/441398a. PMID 16724031.
2. ^ a b c Elizabeth Pennisi (2007). "DNA Study Forces Rethink of What It Means to Be a Gene". Science 316 (5831): 1556–1557. doi:10.1126/science.316.5831.1556. PMID 17569836.
3. ^ Noble, D. (Sep 2008). "Genes and causation" (Free full text). Philosophical transactions. Series A, Mathematical, physical, and engineering sciences 366 (1878): 3001–3015. doi:10.1098/rsta.2008.0086. ISSN 1364-503X. PMID 18559318. http://rsta.royalsocietypublishing.org/cgi/pmidlookup?view=long&pmid=18559318. edit
4. ^ a b Rassoulzadegan M, Grandjean V, Gounon P, Vincent S, Gillot I, Cuzin F (2006). "RNA-mediated non-mendelian inheritance of an epigenetic change in the mouse". Nature 441 (7092): 469–74. doi:10.1038/nature04674 (inactive 2010-03-25). PMID 16724059.
5. ^ Mortazavi A, Williams BA, McCue K, Schaeffer L, Wold B (May 2008). "Mapping and quantifying mammalian transcriptomes by RNA-Seq". Nat. Methods 5 (7): 621. doi:10.1038/nmeth.1226. PMID 18516045.
6. ^ Woodson SA (1998). "Ironing out the kinks: splicing and translation in bacteria". Genes Dev. 12 (9): 1243–7. doi:10.1101/gad.12.9.1243. PMID 9573040. http://genesdev.cshlp.org/content/12/9/1243.full. Retrieved 2009-08-07.
7. ^ Braig M, Schmitt C (2006). "Oncogene-induced senescence: putting the brakes on tumor development". Cancer Res 66 (6): 2881–4. doi:10.1158/0008-5472.CAN-05-4006. PMID 16540631.
8. ^ International Human Genome Sequencing Consortium (2004). "Finishing the euchromatic sequence of the human genome". Nature 431 (7011): 931–45. doi:10.1038/nature03001. PMID 15496913. http://www.nature.com/nature/journal/v431/n7011/full/nature03001.html. Retrieved 2009-08-07.
9. ^ a b Watson JD, Baker TA, Bell SP, Gann A, Levine M, Losick R (2004). Molecular Biology of the Gene (5th ed.). Peason Benjamin Cummings (Cold Spring Harbor Laboratory Press). ISBN 080534635X.
10. ^ a b Vries, H. de (1889) Intracellular Pangenesis [1] ("pangen" definition on page 7 and 40 of this 1910 translation in English)
11. ^ "The Human Genome Project Timeline". http://www.genome.gov/25019879. Retrieved 2006-09-13.
12. ^ a b c d e Mark B. Gerstein et al., "What is a gene, post-ENCODE? History and updated definition," Genome Research 17(6) (2007): 669-681
13. ^ Darwin C. (1868). Animals and Plants under Domestication (1868).
14. ^ Steinman RM, Moberg CL (February 1994). "A triple tribute to the experiment that transformed biology". J. Exp. Med. 179 (2): 379–84. doi:10.1084/jem.179.2.379. PMID 8294854.
15. ^ Min Jou W, Haegeman G, Ysebaert M, Fiers W (1972). "Nucleotide sequence of the gene coding for the bacteriophage MS2 coat protein". Nature 237 (5350): 82–8. doi:10.1038/237082a0. PMID 4555447.
16. ^ Schuler GD, Boguski MS, Stewart EA, et al (October 1996). "A gene map of the human genome". Science 274 (5287): 540–6. doi:10.1126/science.274.5287.540. PMID 8849440. http://www.sciencemag.org/cgi/content/full/274/5287/540.
17. ^ a b Carninci P, Hayashizaki Y (April 2007). "Noncoding RNA transcription beyond annotated genes". Curr. Opin. Genet. Dev. 17 (2): 139–44. doi:10.1016/j.gde.2007.02.008. PMID 17317145.
18. ^ a b Claverie JM (September 2005). "Fewer genes, more noncoding RNA". Science 309 (5740): 1529–30. doi:10.1126/science.1116800. PMID 16141064.
19. ^ Thomas KR, Capecchi MR. Site-directed mutagenesis by gene targeting in mouse embryo-derived stem cells. Cell. 1987;51:503-12
20. ^ The 2007 Nobel Prize in Physiology or Medicine - Press Release
21. ^ a b Deng C. In Celebration of Dr. Mario R. Capecchi's Nobel Prize. Int J Biol Sci 2007; 3:417-419. International Journal of Biological Sciences
22. ^ Mario R. Capecchi
23. ^ Spilianakis & colleagues (2005) Interchromosomal associations between alternatively expressed loci. PMID 15880101
24. ^ Parra & colleagues (2006) Tandem chimerism as a means to increase protein complexity in the human genome. PMID 16344564
25. ^ Kapranov & colleagues (2005) Examples of the complex architecture of the human transcriptome revealed by RACE and high-density tiling arrays. PMID 15998911
Further reading
* Dawkins, Richard (1990). The Selfish Gene. Oxford University Press. ISBN 0-19-286092-5. Google Book Search; first published 1976.
* Dawkins, Richard (1995). River Out of Eden. Basic Books. ISBN 0-465-06990-8.
* Ridley, Matt (1999). Genome: The Autobiography of a Species in 23 Chapters. Fourth Estate. ISBN 0-00-763573-7.
* Witzany (ed), Guenther (2009). Natural Genetic Engineering and Natural Genome Editing. Wiley & Sons. ISBN 1-57331-765-9.
External links
* Comparative Toxicogenomics Database
* DNA From The Beginning - a primer on genes and DNA
* Genes And DNA - Introduction to genes and DNA aimed at non-biologist
* Entrez Gene - a searchable database of genes
* IDconverter - converts gene IDs between public databases
* iHOP - Information Hyperlinked over Proteins
* TranscriptomeBrowser - Gene expression profile analysis
* The Protein Naming Utility, a database to identify and correct deficient gene names
* Genes - an Open Access journal
Retrieved from "http://en.wikipedia.org/"
All text is available under the terms of the GNU Free Documentation License

{kind=link}