
.
Permutation
In mathematics, the notion of permutation is used with several slightly different meanings, all related to the act of permuting (rearranging) objects or values. Informally, a permutation of a set of objects is an arrangement of those objects into a particular order. For example, there are six permutations of the set {1,2,3}, namely (1,2,3), (1,3,2), (2,1,3), (2,3,1), (3,1,2), and (3,2,1). One might define an anagram of a word as a permutation of its letters. The study of permutations in this sense generally belongs to the field of combinatorics.
The number of permutations of n distinct objects is n×(n − 1)×(n − 2)×...×2×1, which number is called "n factorial" and written "n!".
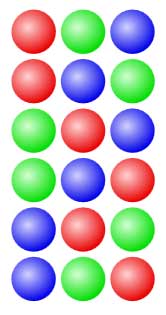
The 6 permutations of 3 balls
Permutations occur, in more or less prominent ways, in almost every domain of mathematics. They often arise when different orderings on certain finite sets are considered, possibly only because one wants to ignore such orderings and needs to know how many configurations are thus identified. For similar reasons permutations arise in the study of sorting algorithms in computer science.
In algebra and particularly in group theory, a permutation of a set S is defined as a bijection from S to itself (i.e., a map S → S for which every element of S occurs exactly once as image value). This is related to the rearrangement of S in which each element s takes the place of the corresponding f(s). The collection of such permutations form a symmetric group. The key to its structure is the possibility to compose permutations: performing two given rearrangements in succession defines a third rearrangement, the composition. Permutations may act on composite objects by rearranging their components, or by certain replacements (substitutions) of symbols.
In elementary combinatorics, the name "permutations and combinations" refers to two related problems, both counting possibilities to select k distinct elements from a set of n elements, where for k-permutations the order of selection is taken into account, but for k-combinations it is ignored. However k-permutations do not correspond to permutations as discussed in this article (unless k = n).
History
The rule to determine the number of permutations of n objects was known in Hindu culture at least as early as around 1150: the Lilavati by the Indian mathematician Bhaskara II contains a passage that translates to
The product of multiplication of the arithmetical series beginning and increasing by unity and continued to the number of places, will be the variations of number with specific figures.[1]
A first case in which seemingly unrelated mathematical questions were studied with the help of permutations occurred around 1770, when Joseph Louis Lagrange, in the study of polynomial equations, observed that properties of the permutations of the roots of an equation are related to the possibilities to solve it. This line of work ultimately resulted, through the work of Évariste Galois, in Galois theory, which gives a complete description of what is possible and impossible with respect to solving polynomial equations (in one unknown) by radicals. In modern mathematics there are many similar situations in which understanding a problem requires studying certain permutations related to it.
Generalities
The notion of permutation is used in the following contexts.
In group theory
In group theory and related areas, one considers permutations of arbitrary sets, even infinite ones. A permutation of a set S is a bijection from S to itself. This allows for permutations to be composed, which allows the definition of groups of permutations. If S is a finite set of n elements, then there are n! permutations of S.
In combinatorics
Permutations of multisets
In combinatorics, a permutation is usually understood to be a sequence containing each element from a finite set once, and only once. The concept of sequence is distinct from that of a set, in that the elements of a sequence appear in some order: the sequence has a first element (unless it is empty), a second element (unless its length is less than 2), and so on. In contrast, the elements in a set have no order; {1, 2, 3} and {3, 2, 1} are different ways to denote the same set. In this sense a permutation of a finite set S of n elements is equivalent to a bijection from {1, 2, ... , n} to S (in which any i is mapped to the i-th element of the sequence), or to a choice of a total ordering on S (for which x < y if x comes before y in the sequence). In this sense there are also n! permutations of S.
There is also a weaker meaning of the term "permutation" that is sometimes used in elementary combinatorics texts, designating those sequences in which no element occurs more than once, but without the requirement to use all elements from a given set. Indeed this use often involves considering sequences of a fixed length k of elements taken from a given set of size n. These objects are also known as sequences without repetition, a term that avoids confusion with the other, more common, meanings of "permutation". The number of such k-permutations of n is denoted variously by such symbols as n Pk, nPk, Pn,k, or P(n,k), and its value is given by the product[2]
\( n\cdot(n-1)\cdot(n-2)\cdots(n-k+1) \)
which is 0 when k > n, and otherwise is equal to
\( \frac{n!}{(n-k)!}. \)
The product is well defined without the assumption that n is a non-negative integer, and is of importance outside combinatorics as well; it is known as the Pochhammer symbol (n)k or as the k-th falling factorial power nk of n.
If M is a finite multiset, then a multiset permutation is a sequence of elements of M in which each element appears exactly as often as is its multiplicity in M. If the multiplicities of the elements of M (taken in some order) are m_1, m_2, ..., m_l and their sum (i.e., the size of M) is n, then the number of multiset permutations of M is given by the multinomial coefficient
\( {n \choose m_1,m_2,\ldots,m_l} = \frac{n!}{m_1!\,m_2!\, \cdots\,m_l!}. \)
Permutations in group theory
Main article: Symmetric group
In group theory, the term permutation of a set means a bijective map, or bijection, from that set onto itself. The set of all permutations of any given set S forms a group, with composition of maps as product and the identity as neutral element. This is the symmetric group of S. Up to isomorphism, this symmetric group only depends on the cardinality of the set, so the nature of elements of S is irrelevant for the structure of the group. Symmetric groups have been studied most in the case of a finite sets, in which case one can assume without loss of generality that S={1,2,...,n} for some natural number n, which defines the symmetric group of degree n, written Sn.
Any subgroup of a symmetric group is called a permutation group. In fact by Cayley's theorem any group is isomorphic to some permutation group, and every finite group to a subgroup of some finite symmetric group. However, permutation groups have more structure than abstract groups, allowing for instance to define the cycle type of an element of a permutation group; different realizations of a group as a permutation group need not be equivalent for this additional structure. For instance S3 is naturally a permutation group, in which any transposition has cycle type (2,1), but the proof of Cayley's theorem realizes S3 as a subgroup of S6 (namely the permutations of the 6 elements of S3 itself), in which permutation group transpositions get cycle type (2,2,2). So in spite of Cayley's theorem, the study of permutation groups differs from the study of abstract groups.
Notation
There are three main notations for permutations of a finite set S. In Cauchy's two-line notation, one lists the elements of S in the first row, and for each one its image under the permutation below it in the second row. For instance, a particular permutation of the set {1,2,3,4,5} can be written as:
\( \sigma=\begin{pmatrix} 1 & 2 & 3 & 4 & 5 \\ 2 & 5 & 4 & 3 & 1\end{pmatrix}; \)
this means that σ satisfies σ(1)=2, σ(2)=5, σ(3)=4, σ(4)=3, and σ(5)=1.
In one-line notation, one gives only the second row of this array, so the one-line notation for the permutation above is 25431. (It is typical to use commas to separate these entries only if some have two or more digits.)
Cycle notation, the third method of notation, focuses on the effect of successively applying the permutation. It expresses the permutation as a product of cycles corresponding to the orbits (with at least two elements) of the permutation; since distinct orbits are disjoint, this is loosely referred to as "the decomposition into disjoint cycles" of the permutation. It works as follows: starting from some element x of S with σ(x) ≠ x, one writes the sequence (x σ(x) σ(σ(x)) ...) of successive images under σ, until the image would be x, at which point one instead closes the parenthesis. The set of values written down forms the orbit (under σ) of x, and the parenthesized expression gives the corresponding cycle of σ. One then continues choosing an element y of S that is not in the orbit already written down, and such that σ(y) ≠ y, and writes down the corresponding cycle, and so on until all elements of S either belong to a cycle written down or are fixed points of σ. Since for every new cycle the starting point can be chosen in different ways, there are in general many different cycle notations for the same permutation; for the example above one has for instance
\( \begin{pmatrix} 1 & 2 & 3 & 4 & 5 \\ 2 & 5 & 4 & 3 & 1\end{pmatrix}=\begin{pmatrix}1 & 2 & 5 \end{pmatrix} \begin{pmatrix}3 & 4 \end{pmatrix} = \begin{pmatrix}3 & 4 \end{pmatrix} \begin{pmatrix}1 & 2 & 5 \end{pmatrix} = \begin{pmatrix}3 & 4 \end{pmatrix} \begin{pmatrix}5 & 1 & 2 \end{pmatrix}. \)
Each cycle (x1 x2 ... xl) of σ denotes a permutation in its own right, namely the one that takes the same values as σ on this orbit (so it maps xi to xi+1 for i < l, and xl to x1), while mapping all other elements of S to themselves. The size l of the orbit is called the length of the cycle. Distinct orbits of σ are by definition disjoint, so the corresponding cycles are easily seen to commute, and σ is the product of its cycles (taken in any order). Therefore the concatenation of cycles in the cycle notation can be interpreted as denoting composition of permutations, whence the name "decomposition" of the permutation. This decomposition is essentially unique: apart from the reordering the cycles in the product, there are no other ways to write σ as a product of cycles (possibly unrelated to the cycles of σ) that have disjoint orbits. The cycle notation is less unique, since each individual cycle can be written in different ways, as in the example above where (5 1 2) denotes the same cycle as (1 2 5) (but (5 2 1) would denote a different permutation).
An orbit of size 1 (a fixed point x in S) has no corresponding cycle, since that permutation would fix x as well as every other element of S, in other words it would be the identity, independently of x. It is possible to include (x) in the cycle notation for σ to stress that σ fixes x (and this is even standard in combinatorics, as described in cycles and fixed points), but this does not correspond to a factor in the (group theoretic) decomposition of σ. If the notion of "cycle" were taken to include the identity permutation, then this would spoil the uniqueness (up to order) of the decomposition of a permutation into disjoint cycles. The decomposition into disjoint cycles of the identity permutation is an empty product; its cycle notation would be empty, so some other notation like e is usually used instead.
Cycles of length two are called transpositions; such permutations merely exchange the place of two elements.
Product and inverse
Main article: Symmetric group
The product of two permutations is defined as their composition as functions, in other words σ·π is the function that maps any element x of the set to σ(π(x)). Note that the rightmost permutation is applied to the argument first, because of the way function application is written. Some authors prefer the leftmost factor acting first, but to that end permutations must be written to the right of their argument, for instance as an exponent, where σ acting on x is written xσ; then the product is defined by xσ·π=(xσ)π. However this gives a different rule for multiplying permutations; this article uses the definition where the rightmost permutation is applied first.
Since the composition of two bijections always gives another bijection, the product of two permutations is again a permutation. Since function composition is associative, so is the product operation on permutations: (σ·π)·ρ=σ·(π·ρ). Therefore, products of more than two permutations are usually written without adding parentheses to express grouping; they are also usually written without a dot or other sign to indicate multiplication.
The identity permutation, which maps every element of the set to itself, is the neutral element for this product. In two-line notation, the identity is
\( \begin{pmatrix}1 & 2 & 3 & \cdots & n \\ 1 & 2 & 3 & \cdots & n\end{pmatrix}. \)
Since bijections have inverses, so do permutations, and the inverse σ−1 of σ is again a permutation. Explicitly, whenever σ(x)=y one also has σ−1(y)=x. In two-line notation the inverse can be obtained by interchanging the two lines (and sorting the columns if one wishes the first line to be in a given order). For instance
\( \begin{pmatrix}1 & 2 & 3 & 4 & 5 \\ 2 & 5 & 4 & 3 & 1\end{pmatrix}^{-1} =\begin{pmatrix}2 & 5 & 4 & 3 & 1\\ 1 & 2 & 3 & 4 & 5 \end{pmatrix} =\begin{pmatrix}1 & 2 & 3 & 4 & 5 \\ 5 & 1 & 4 & 3 & 2\end{pmatrix}. \)
In cycle notation one can reverse the order of the elements in each cycle to obtain a cycle notation for its inverse.
Having an associative product, a neutral element, and inverses for all its elements, makes the set of all permutations of S into a group, called the symmetric group of S.

Composition of permutations corresponds to multiplication of permutation matrices. The binary permutation matrices can be seen as adjacency matrices of directed cycle graphs, which are the most intuitive visualization of permutations, and thus included. These 6 permutations form a group. The 6x6 matrix of 3x3 matrices is its Cayley table.
Every permutation of a finite set can be expressed as the product of transpositions. Moreover, although many such expressions for a given permutation may exist, there can never be among them both expressions with an even number and expressions with an odd number of transpositions. All permutations are then classified as even or odd, according to the parity of the transpositions in any such expression.
Composition of permutations corresponds to multiplication of permutation matrices.
Multiplying permutations written in cycle notation follows no easily described pattern, and the cycles of the product can be entirely different from those of the permutations being composed. However the cycle structure is preserved in the special case of conjugating a permutation σ by another permutation π, which means forming the product π·σ·π−1. Here the cycle notation of the result can be obtained by taking the cycle notation for σ and applying π to all the entries in it.[3]
One can represent a permutation of {1, 2, ..., n} as an n×n matrix. There are two natural ways to do so, but only one for which multiplications of matrices corresponds to multiplication of permutations in the same order: this is the one that associates to σ the matrix M whose entry Mi,j is 1 if i = σ(j), and 0 otherwise. The resulting matrix has exactly one entry 1 in each column and in each row, and is called a permutation matrix.
Here (file) is a list of these matrices for permutations of 4 elements. The Cayley table on the right shows these matrices for permutations of 3 elements.
Permutations in combinatorics
In combinatorics a permutation of a set S with n elements is a listing of the elements of S in some order (each element occurring exactly once). This can be defined formally as a bijection from the set { 1, 2, ..., n } to S. Note that if S equals { 1, 2, ..., n }, then this definition coincides with the definition in group theory. More generally one could use instead of { 1, 2, ..., n } any set equipped with a total ordering of its elements.
One combinatorial property that is related to the group theoretic interpretation of permutations, and can be defined without using a total ordering of S, is the cycle structure of a permutation σ. It is the partition of n describing the lengths of the cycles of σ. Here there is a part "1" in the partition for every fixed point of σ. A permutation that has no fixed point is called a derangement.
Other combinatorial properties however are directly related to the ordering of S, and to the way the permutation relates to it. Here are a number of such properties.
Ascents, descents and runs
An ascent of a permutation σ of n is any position i < n where the following value is bigger than the current one. That is, if σ = σ1σ2...σn, then i is an ascent if σi < σi+1.
For example, the permutation 3452167 has ascents (at positions) 1,2,5,6.
Similarly, a descent is a position i < n with σi > σi+1, so every i with \( 1\leq i<n \) either is an ascent or is a descent of σ.
The number of permutations of n with k ascents is the Eulerian number \( \textstyle\left\langle{n\atop k}\right\rangle; \) this is also the number of permutations of n with k descents.[4]
An ascending run of a permutation is a nonempty increasing contiguous subsequence of the permutation that cannot be extended at either end; it corresponds to a maximal sequence of successive ascents (the latter may be empty: between two successive descents there is still an ascending run of length 1). By contrast an increasing subsequence of a permutation is not necessarily contiguous: it is an increasing sequence of elements obtained from the permutation by omitting the values at some positions. For example, the permutation 2453167 has the ascending runs 245, 3, and 167, while it has an increasing subsequence 2367.
If a permutation has k − 1 descents, then it must be the union of k ascending runs. Hence, the number of permutations of n with k ascending runs is the same as the number \( \textstyle\left\langle{n\atop k-1}\right\rangle \) of permutations with k − 1 descents.[5]
Inversions
Main article: Inversion (discrete mathematics)
An inversion of a permutation σ is a pair (i,j) of positions where the entries of a permutation are in the opposite order: \( i<j \) and \( \sigma_i>\sigma_j \) .[6] So a descent is just an inversion at two adjacent positions. For example, the permutation σ = 23154 has three inversions: (1,3), (1,2), (4,5), for the pairs of entries (3,1), (2,1), (5,4).
Sometimes an inversion is defined as the pair of values (σi,σj) itself whose order is reversed; this makes no difference for the number of inversions, and this pair (reversed) is also an inversion in the above sense for the inverse permutation σ−1. The number of inversions is an important measure for the degree to which the entries of a permutation are out of order; it is the same for σ and for σ−1. To bring a permutation with k inversions into order (i.e., transform it into the identity permutation), by successively applying (right-multiplication by) adjacent transpositions, is always possible and requires a sequence of k such operations. Moreover any reasonable choice for the adjacent transpositions will work: it suffices to choose at each step a transposition of i and i + 1 where i is a descent of the permutation as modified so far (so that the transposition will remove this particular descent, although it might create other descents). This is so because applying such a transposition reduces the number of inversions by 1; also note that as long as this number is not zero, the permutation is not the identity, so it has at least one descent. Bubble sort and insertion sort can be interpreted as particular instances of this procedure to put a sequence into order. Incidentally this procedure proves that any permutation σ can be written as a product of adjacent transpositions; for this one may simply reverse any sequence of such transpositions that transforms σ into the identity. In fact, by enumerating all sequences of adjacent transpositions that would transform σ into the identity, one obtains (after reversal) a complete list of all expressions of minimal length writing σ as a product of adjacent transpositions.
The number of permutations of n with k inversions is expressed by a Mahonian number,[7] it is the coefficient of Xk in the expansion of the product
\( \prod_{m=1}^n\sum_{i=0}^{m-1}X^i=1(1+X)(1+X+X^2)\cdots(1+X+X^2+\cdots+X^{n-1}), \)
which is also known (with q substituted for X) as the q-factorial [n]q! .
Counting sequences without repetition
In this section, a k-permutation of a set S is an ordered sequence of k distinct elements of S. For example, given the set of letters {C, E, G, I, N, R}, the sequence ICE is a 3-permutation, RING and RICE are 4-permutations, NICER and REIGN are 5-permutations, and CRINGE is a 6-permutation; since the latter uses all letters, it is a permutation of the given set in the ordinary combinatorial sense. ENGINE on the other hand is not a permutation, because of the repetitions: it uses the elements E and N twice.
Let n be the size of S, the number of elements available for selection. In constructing a k-permutation, there are n possible choices for the first element of the sequence, and this is then number of 1-permutations. Once it has been chosen, there are n − 1 elements of S left to choose from, so a second element can be chosen in n − 1 ways, giving a total n × (n − 1) possible 2-permutations. For each successive element of the sequence, the number of possibilities decreases by 1 which leads to the number of
n × (n − 1) × (n − 2) ... × (n − k + 1) possible k-permutations.
This gives in particular the number of n-permutations (which contain all elements of S once, and are therefore simply permutations of S):
n × (n − 1) × (n − 2) × ... × 2 × 1,
a number that occurs so frequently in mathematics that it is given a compact notation "n!", and is called "n factorial". These n-permutations are the longest sequences without repetition of elements of S, which is reflected by the fact that the above formula for the number of k-permutations gives zero whenever k > n.
The number of k-permutations of a set of n elements is sometimes denoted by P(n,k) or a similar notation (usually accompanied by a notation for the number of k-combinations of a set of n elements in which the "P" is replaced by "C"). That notation is rarely used in other contexts than that of counting k-permutations, but the expression for the number does arise in many other situations. Being a product of k factors starting at n and decreasing by unit steps, it is called the k-th falling factorial power of n:
\( n^{\underline k}=n\times(n-1)\times(n-2)\times\cdots\times(n-k+1), \)
though many other names and notations are in use, as detailed at Pochhammer symbol. When k ≤ n the factorial power can be completed by additional factors: nk × (n − k)! = n!, which allows writing
\( n^{\underline k}=\frac{n!}{(n-k)!}. \)
The right hand side is often given as expression for then number of k-permutations, but its main merit is using the compact factorial notation. Expressing a product of k factors as a quotient of potentially much larger products, where all factors in the denominator are also explicitly present in the numerator is not particularly efficient; as a method of computation there is the additional danger of overflow or rounding errors. It should also be noted that the expression is undefined when k > n, whereas in those cases the number nk of k-permutations is just 0.
Permutations in computing
Numbering permutations
One way to represent permutations of n is by an integer N with 0 ≤ N < n!, provided convenient methods are given to convert between the number and the usual representation of a permutation as a sequence. This gives the most compact representation of arbitrary permutations, and in computing is particularly attractive when n is small enough that N can be held in a machine word; for 32-bit words this means n ≤ 12, and for 64-bit words this means n ≤ 20. The conversion can be done via the intermediate form of a sequence of numbers dn, dn−1, ..., d2, d1, where di is a non-negative integer less than i (one may omit d1, as it is always 0, but its presence makes the subsequent conversion to a permutation easier to describe). The first step then is simply expression of N in the factorial number system, which is just a particular mixed radix representation, where for numbers up to n! the bases for successive digits are n, n − 1, ..., 2, 1. The second step interprets this sequence as a Lehmer code or (almost equivalently) as an inversion table.
| i \ σi | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Lehmer code |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | × | • | d9 = 5 | |||
| 2 | × | × | • | d8 = 2 | ||||||
| 3 | × | × | × | × | × | • | d7 = 5 | |||
| 4 | • | d6 = 0 | ||||||||
| 5 | × | • | d5 = 1 | |||||||
| 6 | × | × | × | • | d4 = 3 | |||||
| 7 | × | × | • | d3 = 2 | ||||||
| 8 | • | d2 = 0 | ||||||||
| 9 | • | d1 = 0 | ||||||||
| inversion table | 3 | 6 | 1 | 2 | 4 | 0 | 2 | 0 | 0 |
In the Lehmer code for a permutation σ, the number dn represents the choice made for the first term σ1, the number dn−1 represents the choice made for the second term σ1 among the remaining n − 1 elements of the set, and so forth. More precisely, each dn+1−i gives the number of remaining elements strictly less than the term σi. Since those remaining elements are bound to turn up as some later term σj, the digit dn+1−i counts the inversions (i,j) involving i as smaller index (the number of values j for which i < j and σi > σj). The inversion table for σ is quite similar, but here dn+1−k counts the number of inversions (i,j) where k = σj occurs as the smaller of the two values appearing in inverted order.[8] Both encodings can be visualized by an n by n Rothe diagram[9] (named after Heinrich August Rothe) in which dots at (i,σi) mark the entries of the permutation, and a cross at (i,σj) marks the inversion (i,j); by the definition of inversions a cross appears in any square that comes both before the dot (j,σj) in its column, and before the dot (i,σi) in its row. The Lehmer code lists the numbers of crosses in successive rows, while the inversion table lists the numbers of crosses in successive columns; it is just the Lehmer code for the inverse permutation, and vice versa.
To effectively convert a Lehmer code dn, dn−1, ..., d2, d1 into a permutation of an ordered set S, one can start with a list of the elements of S in increasing order, and for i increasing from 1 to n set σi to the element in the list that is preceded by dn+1−i other ones, and remove that element from the list. To convert an inversion table dn, dn−1, ..., d2, d1 into the corresponding permutation, one can traverse the numbers from d1 to dn while inserting the elements of S from largest to smallest into an initially empty sequence; at the step using the number d from the inversion table, the element from S inserted into the sequence at the point where it is preceded by d elements already present. Alternatively one could process the numbers from the inversion table and the elements of S both in the opposite order, starting with a row of n empty slots, and at each step place the element from S into the empty slot that is preceded by d other empty slots.
Converting successive natural numbers to the factorial number system produces those sequences in lexicographic order (as is the case with any mixed radix number system), and further converting them to permutations preserves the lexicographic ordering, provided the Lehmer code interpretation is used (using inversion tables, one gets a different ordering, where one starts by comparing permutations by the place of their entries 1 rather than by the value of their first entries). The sum of the numbers in the factorial number system representation gives the number of inversions of the permutation, and the parity of that sum gives the signature of the permutation. Moreover the positions of the zeroes in the inversion table give the values of left-to-right maxima of the permutation (in the example 6, 8, 9) while the positions of the zeroes in the Lehmer code are the positions of the right-to-left minima (in the example positions the 4, 8, 9 of the values 1, 2, 5); this allows computing the distribution of such extrema among all permutations. A permutation with Lehmer code dn, dn−1, ..., d2, d1 has an ascent n − i if and only if di ≥ di+1.
Algorithms to generate permutations
In computing it may be required to generate permutations of a given sequence of values. The methods best adapted to do this depend on whether one wants some randomly chosen permutations, or all permutations, and in the latter case if a specific ordering is required. Another question is whether possible equality among entries in the given sequence is to be taken into account; if so, one should only generate distinct multiset permutations of the sequence.
An obvious way to generate permutations of n is to generate values for the Lehmer code (possibly using the factorial number system representation of integers up to n!), and convert those into the corresponding permutations. However the latter step, while straightforward, is hard to implement efficiently, because it requires n operations each of selection from a sequence and deletion from it, at an arbitrary position; of the obvious representations of the sequence as an array or a linked list, both require (for different reasons) about n2/4 operations to perform the conversion. With n likely to be rather small (especially if generation of all permutations is needed) that is not too much of a problem, but it turns out that both for random and for systematic generation there are simple alternatives that do considerably better. For this reason it does not seem useful, although certainly possible, to employ a special data structure that would allow performing the conversion from Lehmer code to permutation in O(n log n) time.
Random generation of permutations
Main article: Fisher–Yates shuffle
For generating random permutations of a given sequence of n values, it makes no difference whether one means apply a randomly selected permutation of n to the sequence, or choose a random element from the set of distinct (multiset) permutations of the sequence. This is because, even though in case of repeated values there can be many distinct permutations of n that result in the same permuted sequence, the number of such permutations is the same for each possible result. Unlike for systematic generation, which becomes unfeasible for large n due to the growth of the number n!, there is no reason to assume that n will be small for random generation.
The basic idea to generate a random permutation is to generate at random one of the n! sequences of integers d1,d2,...,dn satisfying 0 ≤ di < i (since d1 is always zero it may be omitted) and to convert it to a permutation through a bijective correspondence. For the latter correspondence one could interpret the (reverse) sequence as a Lehmer code, and this gives a generation method first published in 1938 by Ronald A. Fisher and Frank Yates.[10] While at the time computer implementation was not an issue, this method suffers from the difficulty sketched above to convert from Lehmer code to permutation efficiently. This can be remedied by using a different bijective correspondence: after using di to select an element among i remaining elements of the sequence (for decreasing values of i), rather than removing the element and compacting the sequence by shifting down further elements one place, one swaps the element with the final remaining element. Thus the elements remaining for selection form a consecutive range at each point in time, even though they may not occur in the same order as they did in the original sequence. The mapping from sequence of integers to permutations is somewhat complicated, but it can be seen to produce each permutation in exactly one way, by an immediate induction. When the selected element happens to be the final remaining element, the swap operation can be omitted. This does not occur sufficiently often to warrant testing for the condition, but the final element must be included among the candidates of the selection, to guarantee that all permutations can be generated.
The resulting algorithm for generating a random permutation of a[0], a[1], ..., a[n − 1] can be described as follows in pseudocode:
- for i from n downto 2
- do di ← random element of { 0, ..., i − 1 }
- swap a[di] and a[i − 1]
This can be combined with the initialization of the array a[i] = i as follows:
- for i from 0 to n−1
- do di+1 ← random element of { 0, ..., i }
- a[i] ← a[di+1]
- a[di+1] ← i
If di+1 = i, the first assignment will copy an uninitialized value, but the second will overwrite it with the correct value i.
Generation in lexicographic order
There are many ways to systematically generate all permutations of a given sequence[citation needed]. One classical algorithm, which is both simple and flexible, is based on finding the next permutation in lexicographic ordering, if it exists. It can handle repeated values, for which case it generates the distinct multiset permutations each once. Even for ordinary permutations it is significantly more efficient than generating values for the Lehmer code in lexicographic order (possibly using the factorial number system) and converting those to permutations. To use it, one starts by sorting the sequence in (weakly) increasing order (which gives its lexicographically minimal permutation), and then repeats advancing to the next permutation as long as one is found. The method goes back to Narayana Pandita in 14th century India, and has been frequently rediscovered ever since.[11]
The following algorithm generates the next permutation lexicographically after a given permutation. It changes the given permutation in-place.
- Find the largest index k such that a[k] < a[k + 1]. If no such index exists, the permutation is the last permutation.
- Find the largest index l such that a[k] < a[l]. Since k + 1 is such an index, l is well defined and satisfies k < l.
- Swap a[k] with a[l].
- Reverse the sequence from a[k + 1] up to and including the final element a[n].
After step 1, one knows that all of the elements strictly after position k form a weakly decreasing sequence, so no permutation of these elements will make it advance in lexicographic order; to advance one must increase a[k]. Step 2 finds the smallest value a[l] to replace a[k] by, and swapping them in step 3 leaves the sequence after position k in weakly decreasing order. Reversing this sequence in step 4 then produces its lexicographically minimal permutation, and the lexicographic successor of the initial state for the whole sequence.
Generation with minimal changes
Main article: Steinhaus–Johnson–Trotter algorithm
An alternative to the above algorithm, the Steinhaus–Johnson–Trotter algorithm, generates an ordering on all the permutations of a given sequence with the property that any two consecutive permutations in its output differ by swapping two adjacent values. This ordering on the permutations was known to 17th-century English bell ringers, among whom it was known as "plain changes". One advantage of this method is that the small amount of change from one permutation to the next allows the method to be implemented in constant time per permutation. The same can also easily generate the subset of even permutations, again in constant time per permutation, by skipping every other output permutation.[11]
Software implementations
Calculator functions
Many scientific calculators and computing software have a built-in function for calculating the number of k-permutations of n.
Casio and TI calculators: nPr
HP calculators: PERM[12]
Mathematica: FallingFactorial
Spreadsheet functions
Most spreadsheet software also provides a built-in function for calculating the number of k-permutations of n, called PERMUT in many popular spreadsheets.
Applications
Permutations are used in the interleaver component of the error detection and correction algorithms, such as turbo codes, for example 3GPP Long Term Evolution mobile telecommunication standard uses these ideas (see 3GPP technical specification 36.212 [13]). Such applications raise the question of fast generation of permutation satisfying certain desirable properties. One of the methods is based on the permutation polynomials.
See also
Portal icon Mathematics portal
Alternating permutation
Binomial coefficient
Combination
Combinatorics
Convolution
Cyclic order
Cyclic permutation
Even and odd permutations
Factorial number system
Superpattern
Josephus permutation
List of permutation topics
Levi-Civita symbol
Permutation group
Permutation pattern
Permutation polynomial
Probability
Random permutation
Rencontres numbers
Sorting network
Substitution cipher
Symmetric group
Twelvefold way
Weak order of permutations
Notes
^ N. L. Biggs, The roots of combinatorics, Historia Math. 6 (1979) 109−136
^ Charalambides, Ch A. (2002). Enumerative Combinatorics. CRC Press. p. 42. ISBN 9781584882909.
^ Humphreys (1996), p. 84
^ Combinatorics of Permutations, ISBN 1-58488-434-7, M. Bona, 2004, p. 3
^ Combinatorics of Permutations, ISBN 1-58488-434-7, M. Bona, 2004, p. 4f
^ Combinatorics of Permutations, ISBN 1-58488-434-7, M. Bona, 2004, p. 43
^ Combinatorics of Permutations, ISBN 1-58488-434-7, M. Bona, 2004, p. 43ff
^ a b D. E. Knuth, The Art of Computer Programming, Vol 3, Sorting and Searching, Addison-Wesley (1973), p. 12. This book mentions the Lehmer code (without using that name) as a variant C1,...,Cn of inversion tables in exercise 5.1.1−7 (p. 19), together with two other variants.
^ H. A. Rothe, Sammlung combinatorisch-analytischer Abhandlungen 2 (Leipzig, 1800), 263−305. Cited in,[8] p. 14.
^ Fisher, R.A.; Yates, F. (1948) [1938]. Statistical tables for biological, agricultural and medical research (3rd ed.). London: Oliver & Boyd. pp. 26–27. OCLC 14222135.
^ a b Knuth, D. E. (2005). "Generating All Tuples and Permutations". The Art of Computer Programming. 4, Fascicle 2. Addison-Wesley. pp. 1–26. ISBN 0-201-85393-0.
^ http://h20331.www2.hp.com/Hpsub/downloads/50gProbability-Rearranging_items.pdf
^ 3GPP TS 36.212
References
Miklos Bona. "Combinatorics of Permutations", Chapman Hall-CRC, 2004. ISBN 1-58488-434-7.
Donald Knuth. The Art of Computer Programming, Volume 4: Generating All Tuples and Permutations, Fascicle 2, first printing. Addison-Wesley, 2005. ISBN 0-201-85393-0.
Donald Knuth. The Art of Computer Programming, Volume 3: Sorting and Searching, Second Edition. Addison-Wesley, 1998. ISBN 0-201-89685-0. Section 5.1: Combinatorial Properties of Permutations, pp. 11–72.
Humphreys, J. F.. A course in group theory. Oxford University Press, 1996. ISBN 978-0-19-853459-4
Retrieved from "http://en.wikipedia.org/"
All text is available under the terms of the GNU Free Documentation License
